word不能编辑,如何在word
为什么有人会把可编辑的word文件转换为pdf这种不可编辑的文件呢?
因为有时候我们需要发送给对方直接打印使用,不可编辑就不会导致被修改,从而说不清楚,所以自己用当然word好,给别人观看或者打印就必须要pdf好了,但有时候我们需要把固定的pdf文件转换为可编辑的word文件,这时候如果你随便下载一个工具来转换的话,可能会发现有些加了图片化保护的pdf文件转换后依然不能编辑里面的文字,这样根本就达不到可编辑的目的,下面就教大家怎么转换出可编辑每个字都是word的教程。
一、Word转PDFWord转PDF其实很简单,从office2007开始,微软已经在word中插入这个功能,我们只要打开word文件,然后在保存时选择PDF格式就可以了。
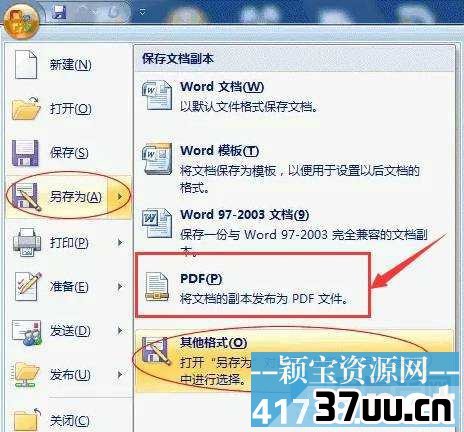
如上图,我们选择 另存为PDF ,或者 另存为其他格式保存类型选pdf就行。
二、PDF转Word 重点来了,我们这里需要用到俄罗斯ABBYY公司的一款OCR识别软件ABBYY FineReader下载它,这款软件真的可以堪称PDF转Word的神器。
真正OCR系统(光学字符识别系统)可以把你的PDF乃至是任何图片的内容直接给扫描出来,然后你还可以直接编辑,再然后你还可以转换成WORD,EXCEL,PPT,TXT等。
使用方法:
1、首先打开一个需要转换的PDF文件,然后看一下这个文件里面有几种语言,是不是有表格、图片等。
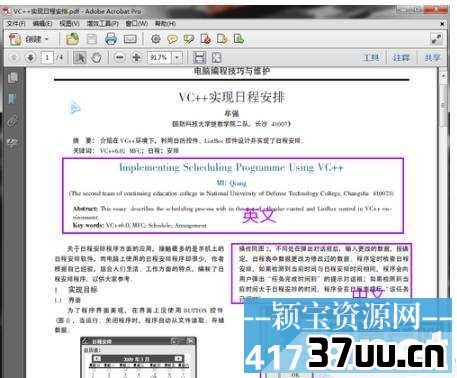
2、然后打开ABBYY finereader 11,点击欢迎界面文档语言下拉选择中的更多语言,弹出语言编辑器界面,我们设置好PDF文件中所包含的几种语言。
因为文件文件中有C++语言的内容,而ABBYY finereader 中正好也有C++的选择,那么我们就毫不犹豫的打上勾。
设置完毕,点击右下角的确定按键。
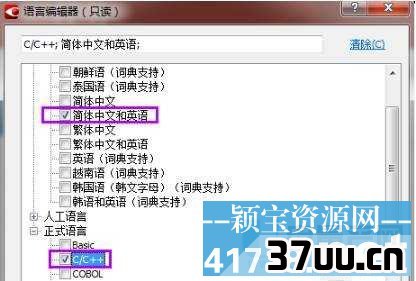
3、回到任务界面,我们是想把PDF转成可编辑的word文件,所以我们点击中间的文件(PDF/图片)到Microsoft Word一项
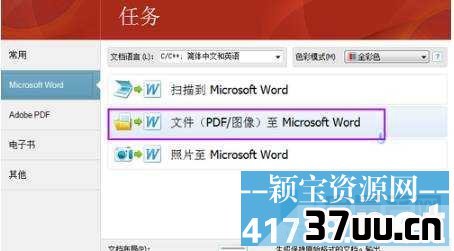
4、弹出文件选择窗口,选择需要转换的PDF文件,注意打开窗口的左下角那几个选项,默认都是打勾的,如果不需要的话可以去掉勾,然后点击打开按键。
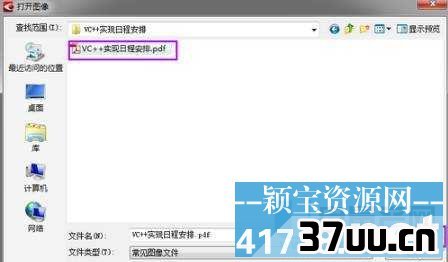
5、ABBYY finereader开始加载文件,并且自动OCR识别处理。
如果页数比较多的话,可能需要花费一些时间,需要耐心等待一下。
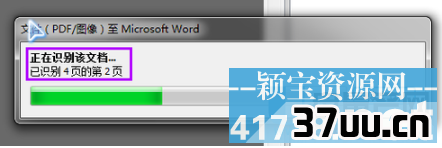
6、由于自动识别会有一些错误,那么我就可以用手动工具进行修正。
我们可以选择不同的工具来修正,比如表格被识别成了普通文字,中间没有线框了,那么我们选择表格工具,然后把文件中的表格的区域选出来,然后右键读取区域就能够手动识别成表格了。
还有如果带有文字的图片被自动识别成了文字了,那么我们可以选择图片工具选出页面中的图片区域,然后在你识别本页面其他部分文字的时候,这个区域就会被识别成图片了。
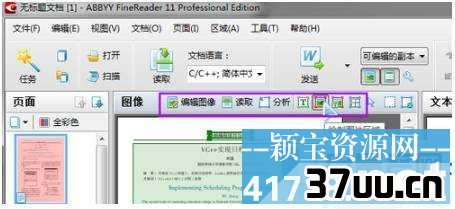
7、编辑图像按键是用来预处理扫描页图片的,因为扫描页有时候会有倾斜、对比度不好、变形等问题,那么先对图像修正一下可以大幅度提高识别的准确率,调整完以后点击右上角的退出图像编辑器按键就可以回到上一界面。
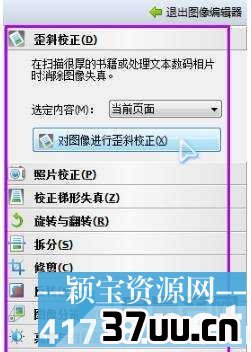
8、识别完毕以后,选择菜单来的文件---将文档另存为---Microsoft Word文档(如果你需要保存为其他格式你可以自己选择)。
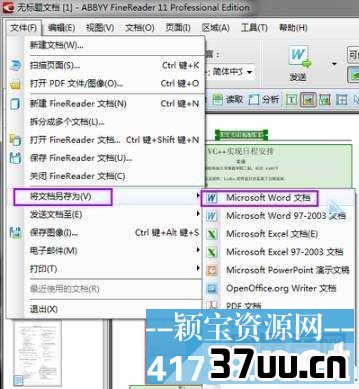
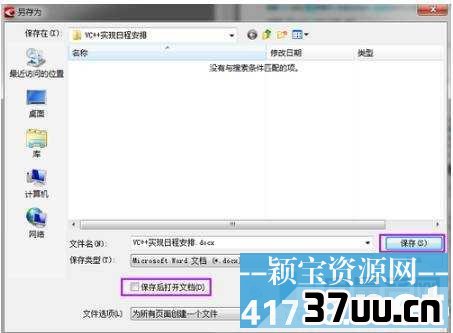
9、弹出保存对话框,选择保存路径,然后保存。
为什么这里写的完美转换呢,因为它支持OCR识别,这个技术就是pdf图片里的文字识别的关键,虽然它也不能完完全全的每个中文字都对,但转换后大大减少了你的工作量,完全不用一个一个字对着图片打出来了,我们需要做的就是核对原文即可,有了OCR,图片,文字,英文,表格都能识别出来,它是目前pdf转word最好用的且最强的工具了,别找那些只有十几M的转换器,根本无法转换图片里的文字的。
版权保护: 本文由 哈晏如 原创,转载请保留链接: https://www.37uu.cn/detail/5632.html
- 上一篇:电脑主机声音大是什么原因,电脑主机没声音
- 下一篇:防火墙和安全网关,网络防火墙